GRPO Amplifies the Success Rate of A Policy via An implicit Fixed Point Iteration
In the previous post, we established that GRPO with verifiable rewards can be seen as a weighted contastive policy optimization, where positive and negative samples are synthetic data sampled from the old policy and labeled via the verifiable reward. In this post we will review our recent preprint that builds on this observation and analyses the dynamics of GRPO and the probability of success of the verifiable reward under GRPO’s optimized policy.
1 GRPO’s Success Rate Recursion
GRPO with no Clipping Equivalent Contrastive Loss formulation
For $\varepsilon >0$, and for $p\in[0,1]$ define the following weights:
$$ \omega_{+,\varepsilon}(p) = \frac{1-p}{\sqrt{p(1-p) +\varepsilon}} $$ $$ \omega_{-,\varepsilon}(p) = \frac{p}{\sqrt{p(1-p) +\varepsilon}} $$
Let $\pi_{\theta_{\text{old}}}$ be the old policy and let $p_{\theta_{\text{old}}}(q)$ be the probability of success of the verifiable reward $r$ under $\pi_{\theta_{\text{old}}}$ for a given prompt $q$: $$ p_{\theta_{\text{old}}}(q) = \mathbb{E}_{o\sim \pi_{\theta_{\text{old}}} (. |q) } 1_{r(q,o)=1} $$
We can write GRPO with no clipping as the following contrastive optimization:
$$ \max_{\theta} L(\theta), $$
where $L(\theta)=$
$$ E_{q} \omega_{+,\varepsilon}(p_{\theta_{\text{old}}}(q)) E_{o\sim \pi_{\theta(. |q) } } 1_{r(q,o)=1} - E_{q} \omega_{-,\varepsilon}(p_{\theta_{\text{old}}}(q)) E_{o\sim \pi_{\theta (. |q)} } 1_{r(q,o)=0}$$ $$ - \beta \mathrm{KL} (\pi_{\theta} || \pi_{\mathrm{ref}}). $$
GRPO Iterations and Optimal Policy
We drop now the optimization on the parameter space and optimize on the space of policies hence GRPO iterations can be written follows for $n\geq 1$:
$$\pi_{n} = arg \max_{\pi} L_{n-1}(\pi) $$ where $L_{n-1}(\pi) =$ $$ \mathbb{E}_{q} (\omega_{+,\varepsilon}\left(p_{n-1}(q)\right) \mathbb{E}_{o\sim \pi(. |q) } 1_{r(q,o)=1}- \omega_{-,\varepsilon}(p_{n-1}(q)) \mathbb{E}_{o\sim \pi (. |q) } 1_{r(q,o)=0})$$ $$ - \beta \mathrm{KL} (\pi|| \pi_{\mathrm{ref}}),$$
and $p_{n-1}(q)$ is the probability of success of the policy $\pi_{n-1}(\cdot|q)$ and $\pi_0= \pi_{\mathrm{ref}}$.
The optimal policy for $n\geq 1$ can be derived as follows:
$$\pi_{n}(o|q) = \frac{1}{Z_{n-1}(q)}\pi_{\mathrm{ref}}(o|q) \exp \left(\frac{1}{\beta} \left( \omega^+_{\varepsilon}(p_{n-1}(q)) 1_{r(q,o)=1} - \omega^-_{\varepsilon}(p_{n-1}(q)) 1_{r(q,o)=0} \right) \right), $$
where
$$ Z_{n-1}(q) = p_{\mathrm{ref}}(q) \exp \left(\frac{1}{\beta} \omega^+_{\varepsilon}(p_{n-1}(q)) \right) + (1-p_{\mathrm{ref}}(q)) \exp \left(- \frac{1}{\beta} \omega^-_{\varepsilon} (p_{n-1} (q)) \right). $$
GRPO’s Probability of Success Recursion
Computing now the success rate $p_{n}(q)$ of the policy $\pi_{n}(\cdot|q)$, and noting $p_{\mathrm{ref}}(q)$ the success rate of $\pi_{\mathrm{ref}}(\cdot|q)$, we obtain the following recursion:
$$ p_{n}(q) = h_{\varepsilon,p_{\mathrm{ref}}(q)}(p_{n-1} (q)) , $$
where $$h_{\varepsilon,p_{\mathrm{ref}}}(p) = \frac{1}{1+ \frac{1-p_{\mathrm{ref}}}{p_{\mathrm{ref}}} \exp \left(-\frac{1}{\beta} \frac{1}{\sqrt{p(1-p) + \varepsilon}}\right) }$$
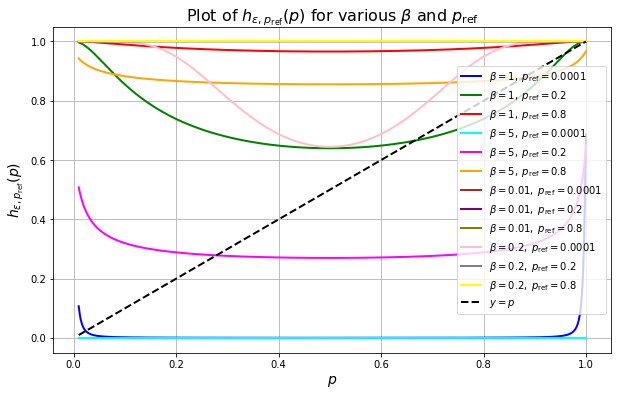
2 GRPO Amplifies Success Rate via An Implicit Fixed Point Iteration
We see that the success rate satisfies a fixed point iterations and the limit of this recursion as $n\to \infty$ for each prompt $q$, $p^*(q)$ (the point in the curves above intersecting the function $h_{\varepsilon,p_{\mathrm{ref}}}$ and the line $y=p$). We show in the paper that under mild conditions on $\beta$:
- the sequence $p_{n}(q)$ converges locally to the the fixed point $p^*(q)$
- the fixed point success rate $p^*(q)$ is guaranteed to be larger then the reference success rate $p_{\mathrm{ref}}(q)$: $p^*(q)>p_{\mathrm{ref}}(q)$.

3 Conclusion
In summary, GRPO with verifiable rewards iterations leads to a fixed point iteration on the success rate of the policy. Under mild conditions, the limit success rate is guaranteed to amplify the success rate of the reference model and the local convergence of the iterates to the limit point is also guaranteed.